





























I – 17
File name : CBM_SR285,A_HDBSR285T19_Italian.doc
version : 2010/04/26
(Nota) : Quando calcolando la capacità di processo nel modo
2–VAR
, x
n
e y
n
sono indipendenti una dall’altra.
Distribuzione di Probabilità
Fasi : ( Vedi Esempio 55. )
1. Sulla base dei gruppi di dati nel modo
1–VAR
premere
[ DATA ] e ci sono tre menù :
DATA–INPUT
,
LIMIT–SET
,
DISTR
. Scegliere
DISTR
e premere [
].
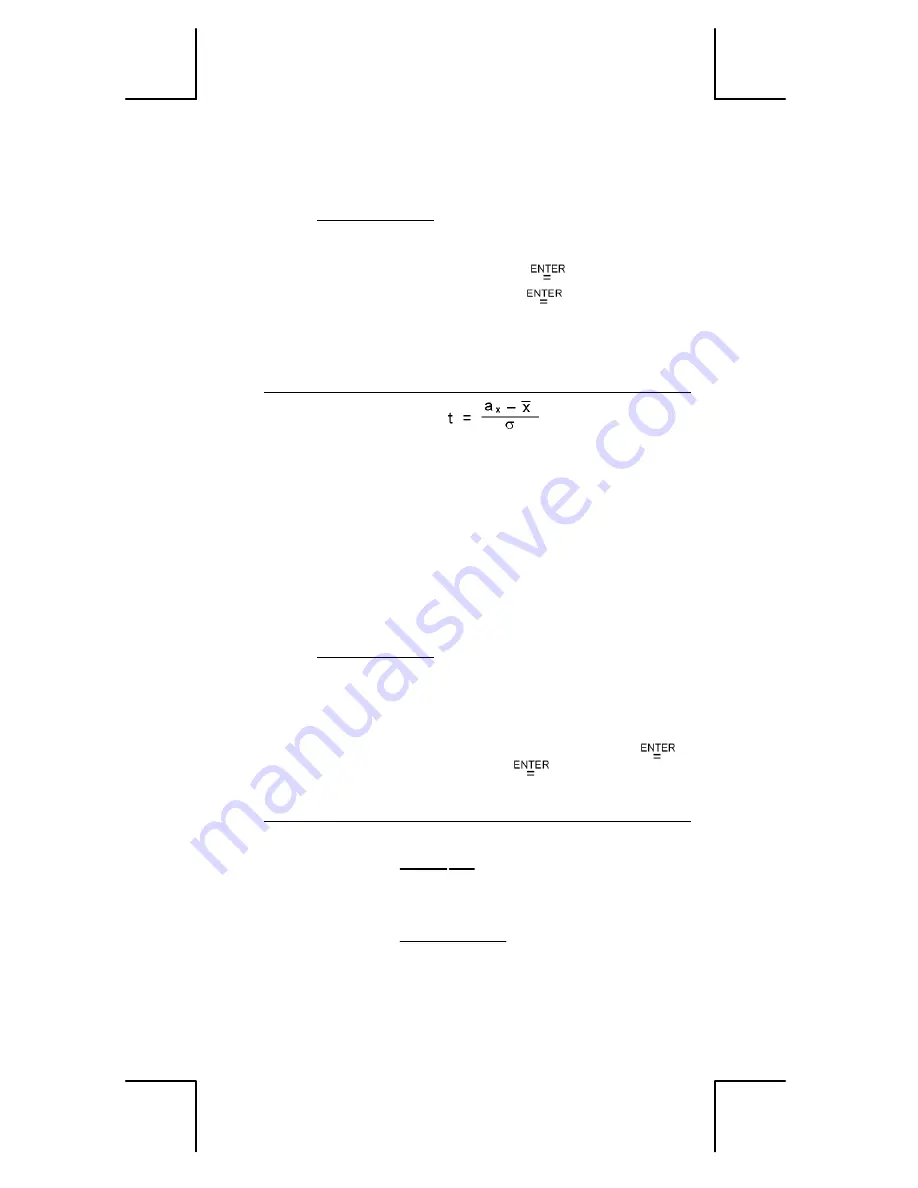
2. Battere un valore
a
x
, poi premere [
].
3. Premere [ STATVAR ] e scorrere attraverso il menù di
risultati statistici con [ ] o [ ] per scoprire le variabili
desiderate di distribuzione di probabilità. (Vedi tabella sotto)
Variabile Significato
t
Valore
test
P ( t )
Rappresenta la frazione cumulativa della
distribuzione normale standard che è inferiore
al valore t
R ( t )
Rappresenta la frazione cumulativa della
distribuzione normale standard che si trova fra il
valore t e 0 R ( t ) =1 – P( t )
Q ( t )
Rappresenta la frazione cumulativa della
distribuzione normale standard che è superiore
al valore t Q ( t ) = | 0.5 – R ( t ) |
Regressione Lineare
Fasi : ( Vedi Esempio 56. )
1. Sulla base dei gruppi di dati nel modo
2–VAR
premere
[ STATVAR ] e scorrere attraverso il menù dei risultati
statistici con [ ] o [ ] per scoprire
a
,
b
, o
r
.
2. Per predire un valore per x (o y) dato un valore per y (o x),
selezionare la variabile x ' (o variabile y '), premere [
],
battere il valore dato,e premere [
] nuovamente. (Vedi
tabella sotto)
Variabile Significato
a
Regressione lineare intercetta-y
∑
∑
−
=
x
n
b
y
a
b
Inclinazione della regressione lineare
∑
∑
−
∑
∑ ∑
−
=
)
)
x
(
x
n
(
)
y
x
xy
n
(
b
2
2



































































