






















10400455-002
©2008-14 Overland Storage, Inc.
85
SnapScale/RAINcloudOS 4.1 Administrator’s Guide
5 – Storage Options
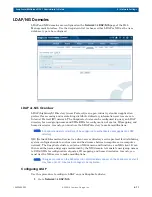
Peer Sets
In a cluster, a node is a file server working in tandem with other nodes. The drives on every
node are grouped into peer sets or hot spares. Each peer set contains two or three drives,
depending on the Data Replication Count, that mirror the same data. To ensure availability,
each drive in a peer set resides in a different node.
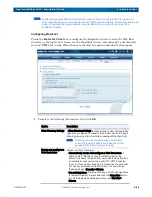
SnapScale aggregates all the storage on the peer sets in the cluster to form a unified data
storage space for network client access. Data access is transparent between the cluster storage
space and the peer sets so that users never directly access the peer sets.
When you create a cluster or add new nodes to an existing cluster, SnapScale automatically
creates peer sets with the available drives. By distributing peer set members throughout the
cluster, the system ensures that content is protected from failure of either individual drives or
entire nodes. When they are created, peer sets are assigned a unique peer set ID.
Nodes can be added to expand cluster storage at any time. Based on the configuration settings,
the additional drives are either used to create more peer sets or left as hot spares. Nodes can
be removed from a cluster for replacement with a new node, and the drives in the replacement
node are automatically synchronized with the existing peer sets.
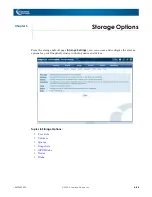
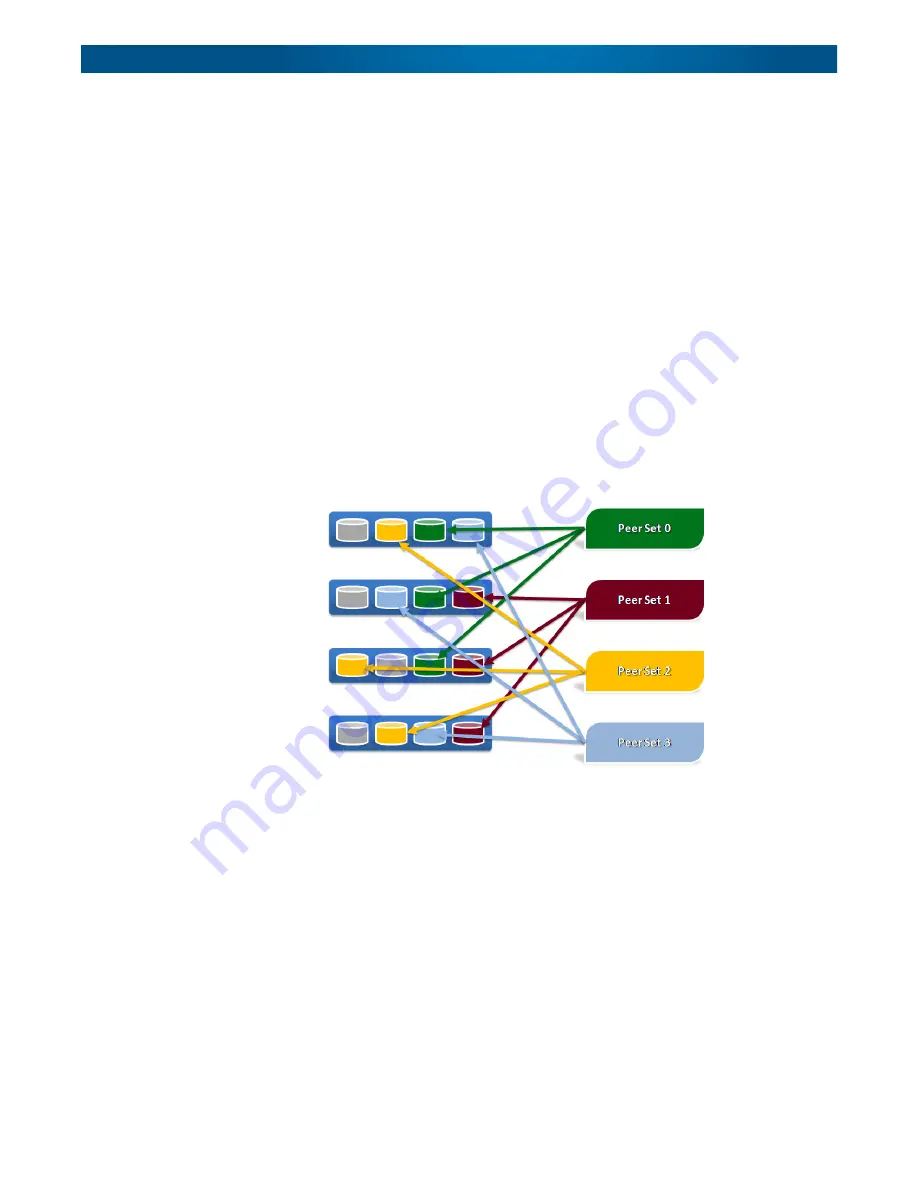
On a four-node cluster configured for 3x replication count, four hot spares, and four drives per
node, the peer set formation might look something like this:
Each peer set has members on three different nodes, shown below as peer set 0, 1, 2, and 3.
Hot spares are automatically distributed throughout the cluster in order to replace any failed
peer set member. When a peer set member fails, a hot spare is assigned from a node on which
the peer set does not already have an active member.
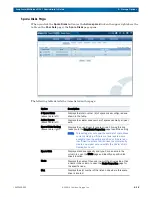
The example above uses a 3x Data Replication Count, which means that each peer set
contains three members, and as a result all data is replicated three times. The cluster can also
be configured for a 2x Data Replication Count, in which case the distribution of two-member
peer sets would be different. The system automatically determines which drives are used to
form each peer set; you cannot choose them.
NOTE: The Data Replication Count can be decreased from 3x to 2x to increase cluster storage, but
cannot be increased from 2x to 3x once the cluster is created.







































































