


























S
CANNING
AND
C
ONFIGURING
O
NE
T
OUCH
115
1.
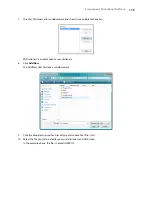
Choose the options you want from the OCR window.
Languages in Document
—click on the language(s) in list that correspond to the languages in the
documents to be scanned. You can click on multiple languages. These are the languages that will be
recognized during the OCR process. For faster and more reliable language recognition, select only the
languages in the documents.
The languages are in alphabetical order. Type the first letter of a language’s name to jump to its section in
the list.
Use languages and dictionaries to improve accuracy
—select this option to automatically check the
validity of the recognized words. An OCR engine looks at each letter or symbol on the page individually, then
“guesses” what the letter or symbol is based on the shape. Therefore, the OCR engine may have more than
one guess for a particular letter or symbol, a “best guess”, a “second-best guess”, and so on. This option tells
the OCR engine to look through the dictionary to validate its best guess for the letters in that word; if its best
guess is not in the dictionary, it checks for the second-best guess, and so on.
For example, if the word “house” appears in the original document but the OCR engine is 75% sure that the
“o” is actually an “a”, the finished document would have the word “hause”. Turning this option on tells the
OCR engine to look at the other letters in the word, check to see which version of the word is in the
dictionary, and output the correct word “house” in the final document.
The OCR engine does not automatically correct misspelled words that were present in the original
document.
When dictionaries are selected, the terms in those dictionaries are used to check the spelling. If this is option
is not selected, User Dictionaries and Professional Dictionaries cannot be selected.
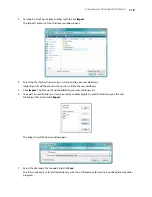
User Dictionary
—a user dictionary is your personal dictionary with words that you want the OCR engine to
reference for better accuracy when converting the document into editable text. For example, if you scan
documents with highly technical terms or acronyms not found in typical dictionaries, you can add them to
your personal dictionary. You can also add names that you expect to be in the documents too. This way, as
the OCR process recognizes each letter or symbol, there is a higher chance that the technical term or name
will be correctly spelled in the final document. You can create multiple user dictionaries. See the section
Creating Your Own Dictionaries
on page 116.
Click the menu arrow and select a user dictionary from the list.
If you select
[none]
as the user dictionary, the text will be validated using the terms in the dictionaries for
the selected languages, as well as any professional dictionaries if they are selected.
The label
[current]
is next to the currently-select user dictionary.
Professional Dictionaries
—these are legal and medical dictionaries containing highly specialized words
and phrases. The options are: Dutch Legal, Dutch Medical, English Financial, English Legal, English Medical,
French Legal, French Medical, German Legal, and German Medical. Select the appropriate dictionary for the
OCR engine to use to validate the scanned text.
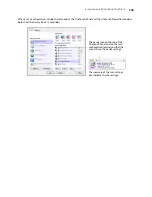
Reject Character
—this is the character that the OCR process inserts for an unrecognizable text character.
For example, if the OCR process cannot recognize the J in REJECT, and ~ is the reject character, the word
would appear as RE~ECT in your document. The ~ is the default reject character.
Type the character you want to use in the Reject Character box. Try to choose a character that will not
appear in your documents.
Missing Character
—this is the character that the OCR process inserts for a missing text character. A missing
text character is one that the OCR process recognizes, but cannot represent because that character is not
available for the selected language. For example, if the document contains the text symbol “Ç” but the OCR
process cannot represent that character, then every place “Ç”
appears, the OCR process substitutes the
missing character symbol. The caret (^) is the default symbol for the missing character.
Summary of Contents for PaperPort Strobe 500
Page 1: ...User s Guide Strobe 500 ...
Page 13: ...VISIONEER STROBE 500 SCANNER USER S GUIDE 12 ...
Page 41: ...VISIONEER STROBE 500 SCANNER USER S GUIDE 40 ...
Page 129: ...VISIONEER STROBE 500 SCANNER USER S GUIDE 128 ...
Page 179: ...VISIONEER STROBE 500 SCANNER USER S GUIDE 178 ...
Page 199: ...INDEX 198 W White Level 171 Word Document 111 X xls file format 111 ...







































































