




























System Configuration and Protection
MPC561/MPC563 Reference Manual, Rev. 1.2
6-16
Freescale Semiconductor
6.1.4.5
Interrupt Overhead Estimation for Enhanced Interrupt Controller Mode
The interrupt overhead consists of two main parts:
•
Storage of general and special purpose registers
•
Recognition of the interrupt source
The interrupt overhead can increase latency, and decrease the overall system performance. The overhead
of register saving time can be reduced by improving the operating system. The number of registers that
should be saved can be reduced if each interrupt event has its own interrupt vector. This solution solves
the interrupt source recognition overhead.
below illustrates the improvements.
Only registers required for the recognition routine are considered to be saved in the calculations below.
Recognition of module internal events/channels is out of the scope of the calculations. See also the typical
interrupt handler flowchart in
.
NOTE
Compiler and bus collision overhead are not included in the calculations.
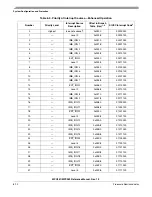
Table 6-5. Interrupt Latency Estimation for Three Typical Cases
MPC561/MPC563
Architecture Without Using
SIVEC
MPC561/MPC563 Architecture
Using SIVEC
MPC561/MPC563
Architecture Using
Enhanced Interrupt
Controller Features
Operation
Details
Interrupt propagation from
request module to RCPU —
8 clocks
Store of some GPR and
SPR—10 clocks
Read SIPEND—4 clocks
Read SIMASK—4 clocks
SIPEND data processing —
20 clocks
(find first set, access to LUT in
the Flash, branches)
Read UIPEND—4 clocks
UIPEND data processing—20
clocks
(find first set, access to LUT in
the Flash, branches)
Interrupt propagation from
request module to RCPU —
8 clocks
Store of some GPR and SPR
—10 clocks
Read SIVEC—4 clocks
Branch to routine—10 clocks
Read UIPEND—4 clocks
UIPEND data processing —
20 clocks
(find first set, access to LUT in
the Flash, branches)
Interrupt propagation from
request module to RCPU —
6 clocks
Store of some GPR and
SPR—10 clocks
Only one branch is executed to
reach the interrupt handler
routine of the device requesting
interrupt servicing—2 clocks
Notes:
If there is a need to enable
nesting of interrupts during
source recognition procedure,
at least 30 clocks should be
added to the interrupt latency
estimation
To use this feature in compressed
mode some undetermined
latency is added to make a
branch to compressed address of
the routine. This latency is
dependant on how the user code
is implemented.
—
Total:
At Least 70-80 Clocks
At Least 50-60 Clocks
20 Clocks
Summary of Contents for MPC561
Page 84: ...MPC561 MPC563 Reference Manual Rev 1 2 lxxxiv Freescale Semiconductor...
Page 144: ...Signal Descriptions MPC561 MPC563 Reference Manual Rev 1 2 2 46 Freescale Semiconductor...
Page 206: ...Central Processing Unit MPC561 MPC563 Reference Manual Rev 1 2 3 62 Freescale Semiconductor...
Page 302: ...Reset MPC561 MPC563 Reference Manual Rev 1 2 7 14 Freescale Semiconductor...
Page 854: ...Time Processor Unit 3 MPC561 MPC563 Reference Manual Rev 1 2 19 24 Freescale Semiconductor...
Page 968: ...Development Support MPC561 MPC563 Reference Manual Rev 1 2 23 54 Freescale Semiconductor...
Page 1144: ...Internal Memory Map MPC561 MPC563 Reference Manual Rev 1 2 B 34 Freescale Semiconductor...
Page 1212: ...TPU3 ROM Functions MPC561 MPC563 Reference Manual Rev 1 2 D 60 Freescale Semiconductor...
Page 1216: ...Memory Access Timing MPC561 MPC563 Reference Manual Rev 1 2 E 4 Freescale Semiconductor...







































































