

























a.
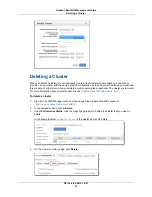
In the Cluster Identifier box, click the cluster that you want to take a snapshot of.
b.
In the Snapshot Identifier box, type a name for the snapshot.
6.
Click Create.
To view details about the snapshot taken and all other snapshots for your AWS account, go to the
snapshots part of the Amazon Redshift console (see
Managing Snapshots Using the Console (p. 54)
).
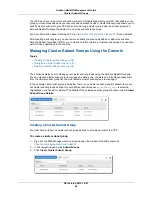
Working with Cluster Performance Data
You can work with cluster performance data using the Performance, Queries, and Loads tabs. For more
information about working with cluster performance, see
Working with Performance Data in the Amazon
Redshift Console (p. 71)
.
Managing Clusters Using AWS SDK for Java
The following Java code example demonstrates common cluster management operations including:
• Creating a cluster.
• Listing metadata about a cluster.
• Modifying configuration options.
After you initiate the request for the cluster to be created, you must wait until the cluster is in the
available
state before you can modify it. This example uses a loop to periodically check the status of the cluster
using the
describeClusters
method. When the cluster is available, the preferred maintenance window
for the cluster is changed.
For step-by-step instructions to run the following example, see
Running Java Examples for Amazon
Redshift Using Eclipse (p. 118)
. You need to update the code and specify a cluster identifier.
import java.io.IOException;
import com.amazonaws.auth.AWSCredentials;
import com.amazonaws.auth.PropertiesCredentials;
import com.amazonaws.services.redshift.AmazonRedshiftClient;
import com.amazonaws.services.redshift.model.*;
public class CreateAndModifyCluster {
public static AmazonRedshiftClient client;
public static String clusterIdentifier = "***provide a cluster identifi
er***";
public static long sleepTime = 20;
API Version 2012-12-01
21
Amazon Redshift Management Guide
Working with Cluster Performance Data







































































